We consider online planning in partially observable domains. Solving the corresponding POMDP problem is a very challenging task, particularly in an online setting. In this research project, we develop approaches that aim to speed up online POMDP planning considering the challenging setting of belief-dependent rewards, which enable advanced capabilities for an agent, such as autonomous uncertainty reduction, informative planning, etc. We do so by considering simplification of different elements of a given decision-making problem and assessing and controlling online the simplification’s impact on the solution/performance.
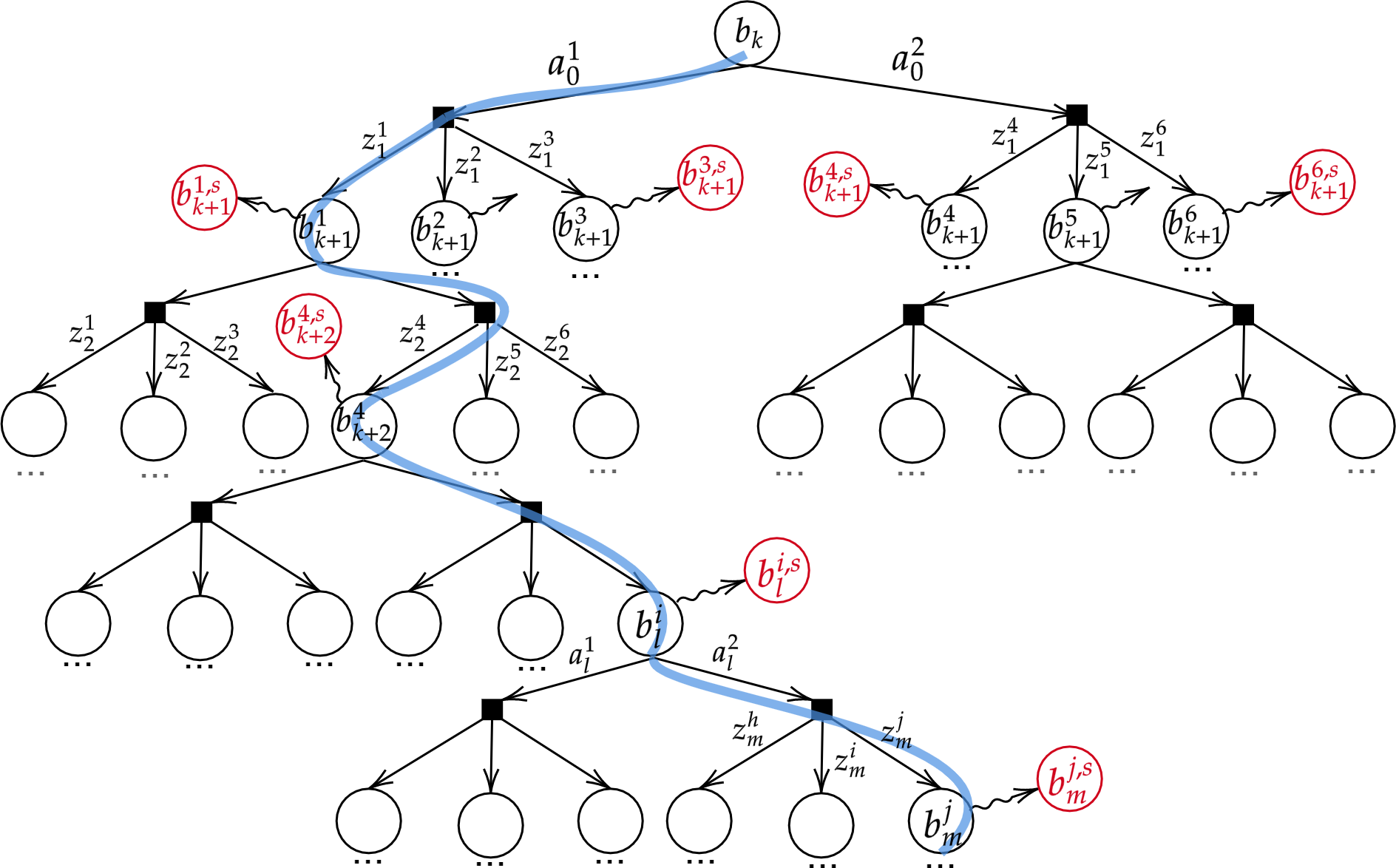
Specifically, in one of the works below we focus on belief simplification, in terms of using only a subset of state samples, and use it to formulate bounds on the corresponding original belief-dependent rewards. These bounds in turn are used to perform branch pruning over the belief tree, in the process of calculating the optimal policy. We further introduce the notion of adaptive simplification, while re-using calculations between different simplification levels, and exploit it to prune, at each level in the belief tree, all branches but one. Therefore, our approach is guaranteed to find the optimal solution of the original problem but with substantial speedup. As a second key contribution, we derive novel analytical bounds for differential entropy, considering a sampling-based belief representation, which we believe are of interest on their own.
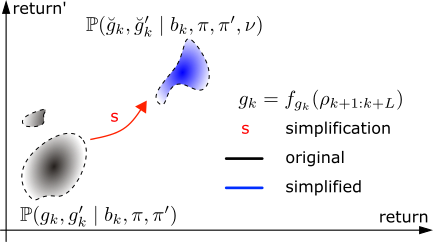
In another work we introduced a framework for quantifying online the effect of a simplification, alongside novel stochastic bounds on the return. Our bounds take advantage of the information encoded in the joint distribution of the original and simplified return. The proposed general framework is applicable to any bounds on the return to capture simplification outcomes.